http://www.cs.sfu.ca/CC/310/pwfong/Lisp/2/tutorial2.html
Recursive functions are usually easier to reason about. Notice how we articulate the correctness of recursive functions in this and the previous tutorial. However, some naive programmers complain that recursive functions are slow when compared to their iterative counter parts. For example, consider the original implementation of factorial we saw in the previous tutorial:
(defun factorial (N)
"Compute the factorial of N."
(if (= N 1)
1
(* N (factorial (- N 1)))))
It is fair to point out that, as recursion unfolds, stack frames will have to be set up, function arguments will have to be pushed into the stack, so on and so forth, resulting in unnecessary runtime overhead not experienced by the iterative counterpart of the above factorial function:
int factorial(int N) {
int A = 1;
while (N != 1) {
A = A * N;
N = N - 1;
}
return A;
}
Because of this and other excuses, programmers conclude that they could write off recursive implementations …
Modern compilers for functional programming languages usually implement tail-recursive call optimizations which automatically translate a certain kind of linear recursion into efficient iterations. A linear recursive function is tail-recursive if the result of each recursive call is returned right away as the value of the function. Let’s examine the implementation of fast-factorial again:
(defun fast-factorial (N)
"A tail-recursive version of factorial."
(fast-factorial-aux N 1))
(defun fast-factorial-aux (N A)
"Multiply A by the factorial of N."
(if (= N 1)
A
(fast-factorial-aux (- N 1) (* N A))))
Notice that, in fast-factorial-aux, there is no work left to be done after the recursive call (fast-factorial-aux (- N 1) (* N A)). Consequently, the compiler will not create new stack frame or push arguments, but instead simply bind (- N 1) to N and (* N A) to A, and jump to the beginning of the function. Such optimization effectively renders fast-factorial as efficient as its iterative counterpart. Notice also the striking structural similarity between the two.
When you implement linearly recursive functions, you are encouraged to restructure it as a tail recursion after you have fully debugged your implementation. Doing so allows the compiler to optimize away stack management code. However, you should do so only after you get the prototype function correctly implemented. Notice that the technique of accumulator variables can be used even when we are not transforming code to tail recursions. For some problems, the use of accumulator variables offers the most natural solutions.
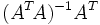 . The pseudo inverse is guaranteed to exist for any full-rank matrix A. However, in some cases the matrix ATA is
. The pseudo inverse is guaranteed to exist for any full-rank matrix A. However, in some cases the matrix ATA is  . However, since x is unknown, this quantity cannot be directly minimized. If a
. However, since x is unknown, this quantity cannot be directly minimized. If a 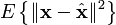 . The least squares method is often applied when no prior is known. Surprisingly, however, better estimators can be constructed, an effect known as
. The least squares method is often applied when no prior is known. Surprisingly, however, better estimators can be constructed, an effect known as 